Computer Science/DataBase
트랜잭션(2)
J._.cobb
2022. 4. 22. 01:50
로킹(locking)
- 데이터 항목을 로킹 하는 개념은 동시에 수행되는 트랜잭션들의 동시성을 제어하기 위해서 가장 널리 사용되는 기법
- 로크(lock)는 데이터베이스 내의 각 데이터 항목과 연관된 하나의 변수
- 각 트랜잭션이 수행을 시작하여 데이터 항목을 접근할 때마다 요청한 로크에 관한 정보는 로크 테이블(lock table) 등에 유지됨
- 트랜잭션에서 갱신을 목적으로 데이터 항목을 접근할 때는 독점 로크(X-lock, eXclusive lock)를 요청함 → 배타적, 다른 트랜잭션과 공유하지 않음, 한 번에 하나의 트랜잭션만 수행
- 트랜잭션에서 읽을 목적으로 데이터 항목을 접근할 때는 공유 로크(S-lock, Shared lock)를 요청함 → 어떤 트랜잭션이 접근했는지 알아야 하기 때문
- 트랜잭션이 데이터 항목에 대한 접근을 끝낸 후에 로크를 해제(unlock)함
2단계 로킹 프로토콜(2-phase locking protocol)
- 로크를 요청하는 것과 로크를 해제하는 것이 2단계로 이루어짐
- 로크 확장 단계가 지난 후에 로크 수축 단계에 들어감
- 일단 로크를 한 개라도 해제하면 로크 수축 단계에 들어감
- 확장 단계에서는 로크 걸기만 가능
- 수축 단계에서는 로크 해제만 가능
- 로크 확장 단계(1단계)
- 로크 확장 단계에서는 트랜잭션이 데이터 항목에 대하여 새로운 로크를 요청할 수 있지만 보유하고 있던 로크를 하나라도 해제할 수 없음
- 로크 수축 단계(2단계)
- 로크 수축 단계에서는 보유하고 있던 로크를 해제할 수 있지만 새로운 로크를 요청할 수 없음
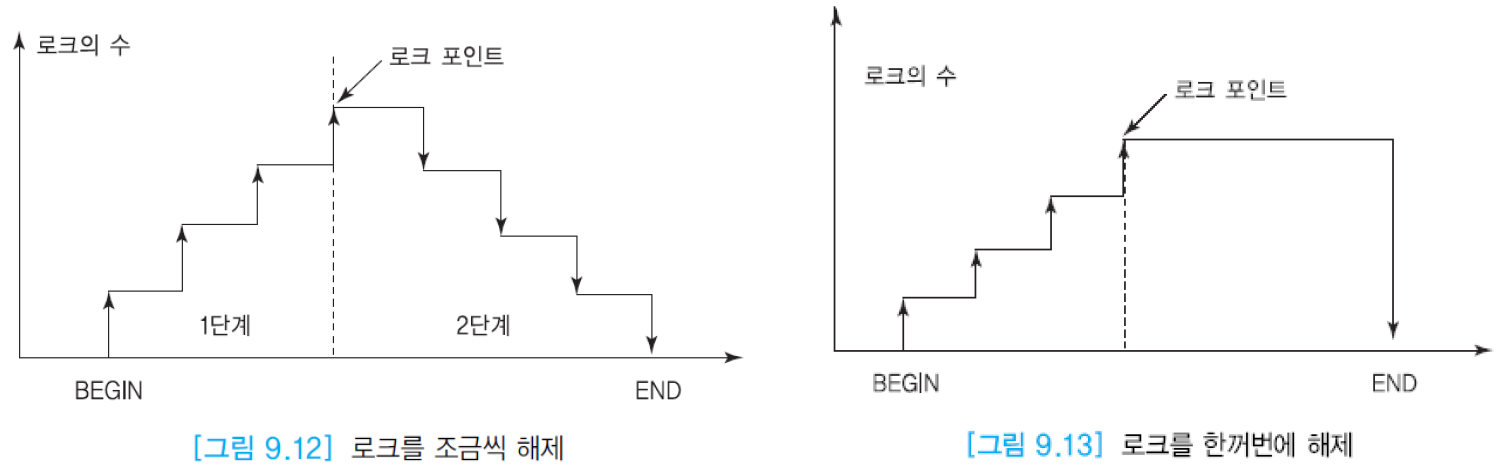
- 로크 수축 단계에서는 로크를 조금씩 해제할 수도 있고 트랜잭션이 완료 시점에 이르렀을 때 한꺼번에 모든 로크를 해제할 수도 있음
- 일반적으로 한꺼번에 해제하는 방식이 사용됨
- 로크 포인트(lock point)는 한 트랜잭션에서 필요로 하는 모든 로크를 걸어놓은 시점
데드록(deadlock)
- 2단계 로킹 프로토콜에서는 데드록이 발생할 수 있음
- 데드록은 두 개 잇아의 트랜잭션들이 서로 상대방이 보유하고 있는 로크를 요청하면서 기다리고 있는 상태를 말함
- 데드록을 해결하기 위해서는 데드록을 방지하는 기법이나, 데드록을 탐지하고 희생자를 선정하여 데드록을 푸는 기법 등을 사용함
- 데드록의 발생
- T1이 X에 대해 독점 로크를 요청하여 허가받음
- T2이 Y에 대해 독점 로크를 요청하여 허가받음
- T1이 Y에 대해 공유 로크나 독점 로크를 요청하면 로크가 해제될 때까지 기다리게 됨
- T2가 X에 대해 공유 로크나 독점 로크를 요청하면 로크가 해제될 때까지 기다리게 됨

다중 로크 단위(multiple granularity)
- 대부분의 트랜잭션들이 소수의 튜플들을 접근하는 데이터베이스 응용에서는 튜플 단위로 로크를 해도 로크 테이블을 다루는 시간이 오래 걸리지 않음
- 트랜잭션들이 많은 튜플을 접근하는 데이터베이스 응용에서 튜플 단위로만 로크를 한다면 로크 테이블에서 로크 충돌을 검사하고, 로크 정보를 기록하는 시간이 오래 걸림
- 트랜잭션이 접근하는 튜플의 수에 따라 로크를 하는 데이터 항목의 단위를 구분하는 것이 필요함
- 한 트랜잭션에서 로크 할 수 있는 데이터 항목이 두 가지 이상 있으면 다중 로크 단위라고 말함
- 데이터베이스에서 로크할 수 있는 단위로는 데이터베이스, 릴레이션, 디스크 블록, 튜플 등

- 일반적으로 DBMS는 각 트랜잭션에서 접근하는 튜플 수에 따라 자동적으로 로크 단위를 조정함
- 로크 단위가 작을수록 로킹에 따른 오버헤드가 증가함
- 로크 단위가 작을수록 동시성의 정도는 증가함
팬텀 문제(phantom problem)
- 두 개의 트랜잭션 T1과 T2가 하나의 릴레이션에 대해서 T1 → T2 → T1의 순서대로 수행된다고 가정
- T1에서는 사원들의 이름을 검색하는 동일한 SELECT문을 수행
- T2에서는 사원의 튜플을 한 개 삽입하는 INSERT문 수행

회복의 필요성
- 어떤 트랜잭션 T를 수행하는 도중에 시스템이 다운되었을 때, T의 수행 효과가 디스크의 데이터베이스에 일부 반영되었을 수 있음
- 어떻게 T의 수행을 취소하여 원자성을 보장할 것인가?
- 또한 트랜잭션 T가 완룐된 직후에 시스템이 다운되면 T의 모든 갱신 효과가 주기억 장치로부터 기록되지 않았을 수 있음
- 어떻게 T의 수행 결과가 데이터베이스에 완전하게 반영되도록 하여 지속성을 보장할 것인가?
- 디스크의 헤드 등이 고장 나서 디스크의 데이터베이스를 접근할 수 없다면 어떻게 할 것인가?
회복의 개요
- 여러 응용 프로그램이 주기억 장치 버퍼 내의 동일한 데이터베이스 항목을 갱신한 후에 디스크에 기록함으로써 성능을 향상하는 것이 중요함
- 버퍼의 내용을 디스크에 기록하는 것을 간으하면 최대한 줄이는 것이 일반적
- ex) 버퍼가 꽉 찼을 때 또는 트랜잭션이 완료될 때 버퍼의 내용이 디스크에 기록될 수 있음
- 트랜잭션이 버퍼에는 갱신 사항을 반영했지만 버퍼의 내용이 디스크에 기록되기 전에 고장이 발생할 수 있음
- 고장이 발생하기 전에 트랜잭션이 완료 명령을 수행했다면 회복 모듈은 이 트랜잭션의 갱신 사항을 재수행(REDO)하여 트랜잭션의 갱신이 지속성을 갖도록 해야 함
- 고장이 발생하기 전에 트랜잭션이 완료 명령을 수행하지 못했다면 원자성을 보장하기 위해서 이 트랜잭션이 데이터베이스에 반영했을 가능성이 있는 갱신 사항을 취소(UNDO)해야 함
저장 장치의 유형
- 주기억 장치와 같은 휘발성 저장 장치에 들어 있는 내용은 시스템이 다운된 후에 모두 사라짐
- 디스크와 같은 비휘발성 저장 장치에 들어 있는 내용은 디스크 헤드 등이 손상을 입지 않는 한 시스템이 다운된 후에도 유지됨
- 안전 저장 장치(stable storage)는 모든 유형의 고장을 견딜 수 있는 저장 장치를 의미
- 두 개 이상의 비휘발성 저장 장치가 동시에 고장 날 가능성이 매우 낮으므로 비휘발성 저장 장치에 두 개 이상의 사본을 중복해서 저장함으로써 안전 저장 장치를 구현함
재해적 고장과 비재해적 고장
- 재해적 고장
- 디스크가 손상을 입어서 데이터베이스를 읽을 수 없는 고장
- 재해적 고장으로부터의 회복은 데이터베이스를 백업해 놓은 자기 테이프를 기반으로 함
- 비재해적 고장
- 그 이외의 고장
- 대부분의 회복 알고리즘들은 비재해적 고장에 적용됨
- 로그를 기반으로 한 즉시 갱신, 로그를 기반으로 한 지연 갱신, 그림자 페이징(shadow paging, 항상 새로운 페이지를 생성해서 갱신함)등 여러 알고리즘
- 대부분의 상용 DBMS에서 로그를 기반으로 한 즉시 갱신 방식을 사용
로그를 사용한 즉시 갱신
- 즉시 갱신에서는 트랜잭션이 데이터베이스를 갱신한 사항이 주기억 장치의 버퍼에 유지되다가 트랜잭션이 완료되기 전이라도 디스크의 데이터베이스에 기록될 수 있음
- 데이터베이스에는 완료된 트랜잭션의 수행 결과뿐만 아니라 철회된 트랜잭션의 수행 결과도 반영될 수 있음
- 트랜잭션의 원자성과 지속성을 보장하기 위해 DBMS는 로그라고 부르는 특별한 파일을 유지함
- 데이터베이스의 항목에 영향을 미치는 모든 트랜잭션의 연산들에 대해서 로그 레코드를 기록함
- 각 로그 레코드는 로그 순서 번호(LSN: Log Sequence Number)로 식별됨

출처